Designing & Implementing a Production-Grade DevOps Portfolio
1. Introduction
Traditional engineering portfolios often focus heavily on visual aesthetics and static project
descriptions. While effective for frontend roles, they rarely demonstrate the operational rigor required
in a DevOps or Systems Engineering context. An engineering system is better understood through its
architecture and the decisions that govern its lifecycle.
This note explains why I chose to treat my portfolio not as a website, but as a small-scale production
platform. By applying production-grade standards to a personal project, I can demonstrate engineering
logic through live artifacts, instrumented metrics, and documented trade-offs rather than marketing
claims.
2. Design Principles
The implementation followed three core principles designed to reflect professional engineering standards:
Simplicity over complexity: Avoid over-engineering. Each component exists to solve
a specific problem. If a static solution suffices, dynamic overhead is rejected.
Automation mindset: If a task must be repeated, it must be automated. This applies
to deployment, image processing, and metrics ingestion.
Observability over aesthetics: While clean design is important for usability, the
ability to measure how the system delivers value—through CI/CD signals and DORA metrics—is
prioritized.
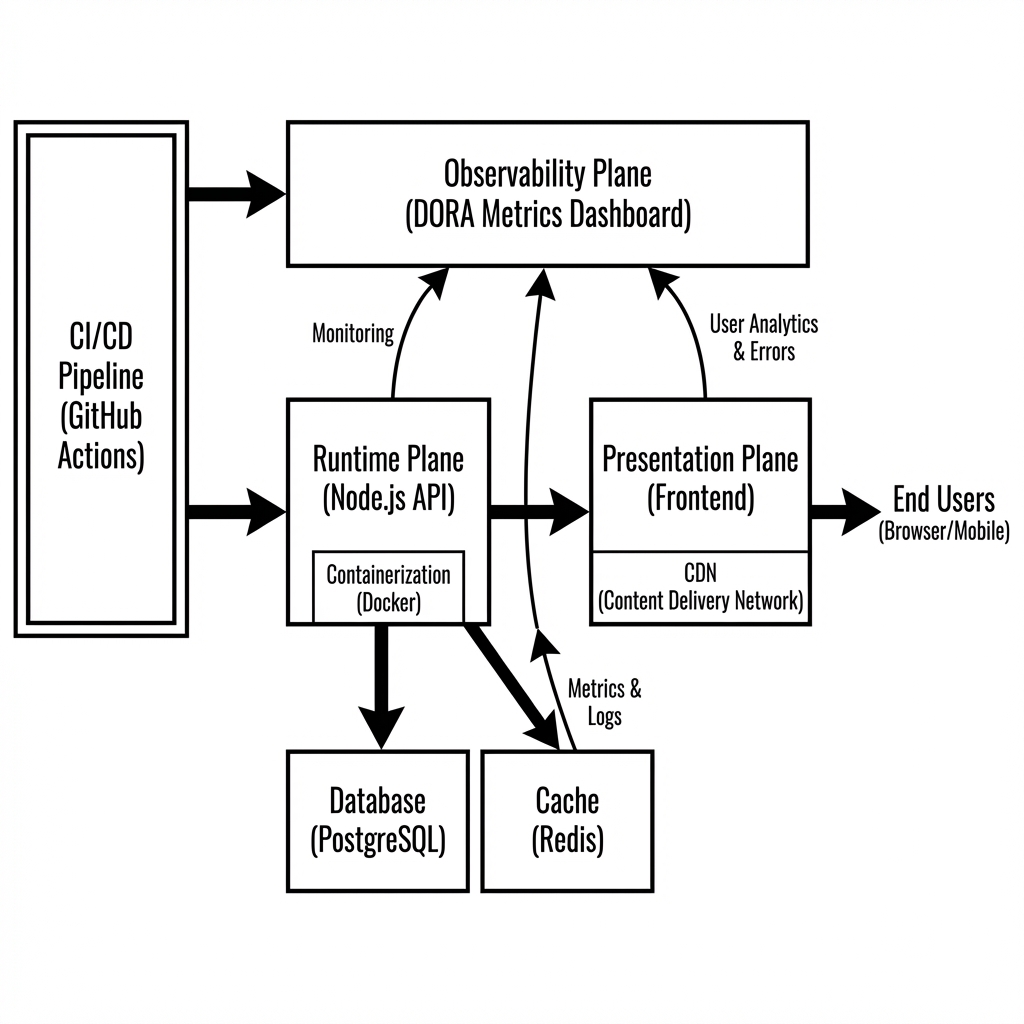
3. Architecture Overview
Figure 1:
High-level system architecture showing plane separation and metrics flow.
The system utilizes a balanced architecture to optimize for performance and functional transparency. The
presentation plane is static-first, ensuring high availability and a minimal attack surface. The runtime
plane handles instrumented events and dynamic operations like metric processing.
The platform is containerized using Docker and served via a Node.js backend.
This choice supports environment parity, allowing the same configuration to run on a local development
machine or a production cloud environment. This setup allows for future growth, such as adding localized
search or more complex observability hooks, without rebuilding the foundation.
4. DevOps & Engineering Decisions
Several technical decisions were made during development to ensure maintainability and production
readiness:
CI/CD Philosophy: I utilize GitHub Actions for a gated deployment strategy. Changes
are validated in an ephemeral environment before merging to production. This ensures that the
production system remains immutable and reliable.
Figure 2:
Automated CI/CD pipeline execution with gated validation stages.
Environment Separation: Credentials and configurations are managed via environment
variables (.env). This prevents secrets from entering version control and allows for
seamless transitions between dev, staging, and production.
Tooling Selection: Express was chosen for the backend due to its lightweight
profile and vast middleware ecosystem, which is ideal for creating simple API endpoints for contact
handling and metric ingestion.
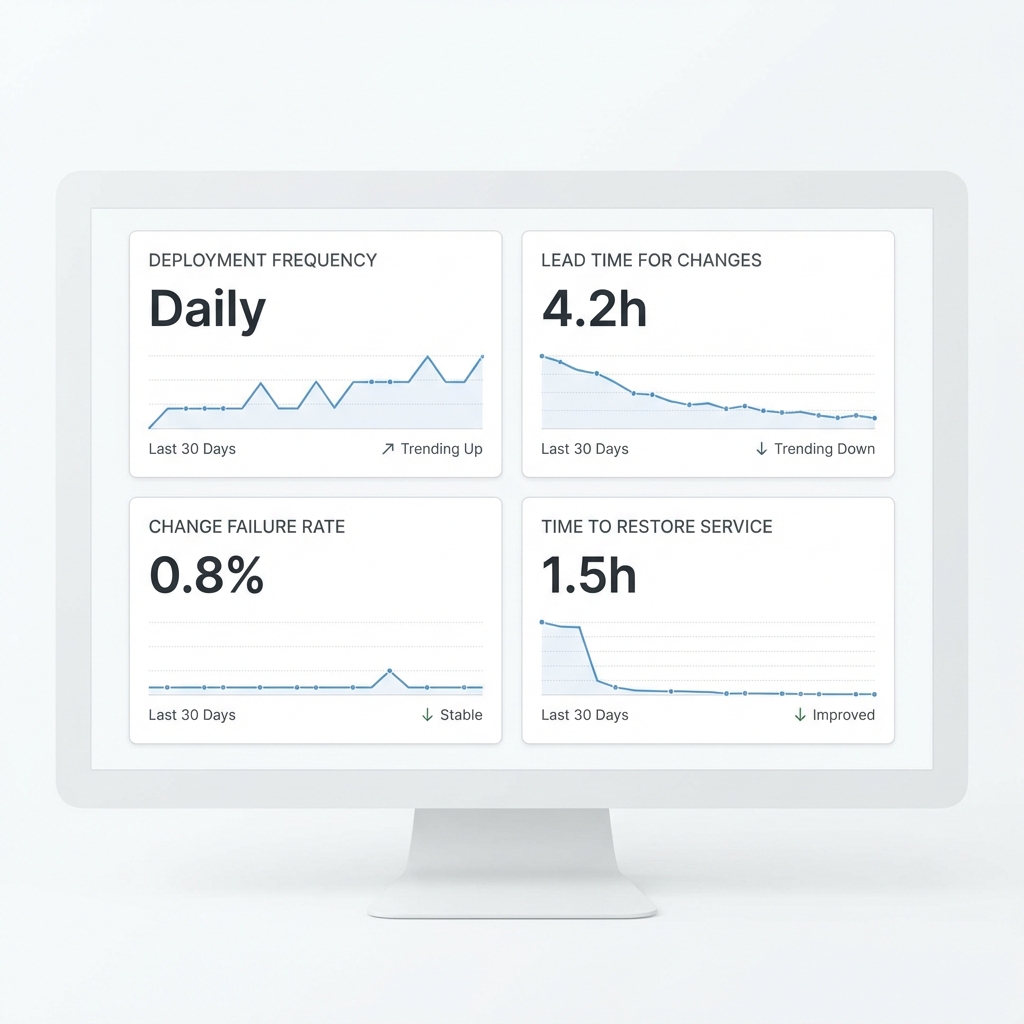
5. Metrics & Engineering Visibility
Figure 3:
Live DORA metrics visualization sourced from CI/CD production pipelines.
A central feature of this platform is the integration of DORA (DevOps Research and Assessment)
metrics. These metrics—Deployment Frequency, Lead Time for Changes, Change Failure Rate,
and Time to Restore—are industry standards for measuring delivery performance.
Integrating these metrics serves a dual purpose: first, it provides empirical evidence of the platform's
stability. Second, it shifts the portfolio from a silent page to an observable system. The dashboard is
accessible via a dedicated Live
Metrics Dashboard, ensuring that technical teams can inspect real delivery data
without being forced through a marketing funnel.
6. Engineering Notes Philosophy
Engineering Notes are distinctive from traditional blog posts. While blogs often follow trends or focus
on high-level tutorials, these notes serve as a technical knowledge base. They document the
"why" behind the "what."
Future entries will bypass generic content to focus on real-world engineering challenges, including:
Root cause analysis of infrastructure failures.
Performance trade-offs in cloud-native architectures.
The evolution of CI/CD pipelines as complexity grows.
Infrastructure as Code (IaC) trade-offs and modularity.
Monitoring and observability anti-patterns.
7. What I’d Improve Next
No production system is perfect. Future refactoring will focus on increasing automation in Infrastructure
as Code (IaC) by fully migrating local resource definitions to Terraform modules. Additionally, I intend
to implement more granular instrumentation to capture service-level indicators (SLIs) beyond standard
deployment metrics.
Maintainability will be enhanced by automating dependency updates and implementing more robust automated
testing for both the backend logic and frontend reliability.
8. Conclusion
Treating a portfolio as a production-grade system provides a baseline for technical communication. It
converts abstract claims into verifiable engineering artifacts. These notes will evolve alongside the
platform, serving as a long-term record of system design and operational learning.
Jan 2026 • Infrastructure • 6 min de lecture
Conception et architecture d'un portfolio DevOps (Production-Grade)
1. Introduction
Les portfolios d'ingénierie traditionnels se concentrent souvent sur l'esthétique visuelle et les
descriptions statiques de projets. Bien que efficaces pour les rôles frontend, ils démontrent rarement
la rigueur opérationnelle requise dans un contexte DevOps ou d'ingénierie système. Un système
d'ingénierie se comprend mieux à travers son architecture et les décisions qui régissent son cycle de
vie.
Cette note explique pourquoi j'ai choisi de traiter mon portfolio non pas comme un simple site web, mais
comme une plateforme de production à petite échelle. En appliquant des standards de niveau production à
un projet personnel, je peux démontrer une logique d'ingénierie via des artefacts réels, des métriques
instrumentées et des compromis documentés plutôt que par de simples arguments marketing.
2. Principes de Conception
L'implémentation a suivi trois principes fondamentaux conçus pour refléter les standards professionnels
de l'ingénierie :
La simplicité avant la complexité : Éviter de sur-concevoir (over-engineering).
Chaque composant existe pour résoudre un problème spécifique. Si une solution statique suffit, le
surcoût dynamique est rejeté.
Mentalité d'automatisation : Si une tâche doit être répétée, elle doit être
automatisée. Cela s'applique au déploiement, au traitement des images et à l'ingestion des
métriques.
L'observabilité avant l'esthétique : Bien qu'un design épuré soit important pour
l'utilisabilité, la capacité à mesurer comment le système délivre de la valeur—à travers les signaux
CI/CD et les métriques DORA—est priorisée.
3. Aperçu de l'Architecture
Figure 1 :
Architecture système montrant la séparation des plans et le flux de métriques.
Le système utilise une architecture équilibrée pour optimiser les performances et la transparence
fonctionnelle. Le plan de présentation est statique-first, garantissant une haute disponibilité et une
surface d'attaque minimale. Le plan d'exécution gère les événements instrumentés et les opérations
dynamiques comme le traitement des métriques.
La plateforme est conteneurisée à l'aide de Docker et servie via un backend
Node.js. Ce choix supporte la parité des environnements, permettant à la même configuration
de s'exécuter sur une machine de développement locale ou un environnement cloud de production. Cette
configuration permet une croissance future, comme l'ajout d'une recherche localisée ou de hooks
d'observabilité plus complexes, sans reconstruire la base.
4. Décisions DevOps & Ingénierie
Plusieurs décisions techniques ont été prises lors du développement pour assurer la maintenabilité et la
préparation à la production :
Philosophie CI/CD : J'utilise GitHub Actions pour une stratégie de déploiement
contrôlée. Les changements sont validés dans un environnement éphémère avant d'être fusionnés en
production. Cela garantit que le système de production reste immuable et fiable.
Figure 2 :
Exécution automatisée du pipeline CI/CD avec étapes de validation.
Séparation des Environnements : Les identifiants et les configurations sont gérés
via des variables d'environnement (.env). Cela empêche les secrets d'entrer dans le
contrôle de version et permet des transitions fluides entre dev, staging et production.
Sélection des Outils : Express a été choisi pour le backend en raison de son profil
léger et de son vaste écosystème de middlewares, ce qui est idéal pour créer des points de
terminaison API simples pour la gestion des contacts et l'ingestion de métriques.
5. Métriques & Visibilité d'Ingénierie
Figure 3 :
Visualisation des métriques DORA extraites des pipelines de production.
Une caractéristique centrale de cette plateforme est l'intégration des métriques DORA (DevOps
Research and Assessment). Ces métriques—Fréquence de déploiement, Délai de mise en œuvre
des changements, Taux d'échec des changements et Délai de rétablissement du service—sont les standards
de l'industrie pour mesurer la performance de livraison.
L'intégration de ces métriques sert un double objectif : premièrement, elle fournit des preuves
empiriques de la stabilité de la plateforme. Deuxièmement, elle fait passer le portfolio d'une page
silencieuse à un système observable. Le tableau de bord est accessible via des contrôles dédiés,
garantissant que les équipes techniques peuvent inspecter les données de livraison réelles sans être
forcées de passer par un entonnoir marketing.
Le tableau de bord est accessible via un Tableau
de bord Metrics en direct, garantissant que les équipes techniques peuvent inspecter les données
de livraison réelles.
6. Philosophie des Notes d'Ingénierie
Les Notes d'Ingénierie se distinguent des articles de blog traditionnels. Alors que les blogs suivent
souvent les tendances ou se concentrent sur des tutoriels de haut niveau, ces notes servent de base de
connaissances techniques. Elles documentent le « pourquoi » derrière le « quoi ».
Les prochaines entrées délaisseront le contenu générique pour se concentrer sur les défis d'ingénierie
réels, notamment :
Analyse des causes racines des défaillances d'infrastructure.
Compromis de performance dans les architectures cloud-native.
L'évolution des pipelines CI/CD à mesure que la complexité croît.
Les compromis et la modularité de l'Infrastructure as Code (IaC).
Les anti-patterns de monitoring et d'observabilité.
7. Prochaines Améliorations
Aucun système de production n'est parfait. Les futurs refactoring se concentreront sur l'augmentation de
l'automatisation de l'Infrastructure as Code (IaC) en migrant complètement les définitions de ressources
locales vers des modules Terraform. De plus, j'ai l'intention de mettre en place une instrumentation
plus granulaire pour capturer des indicateurs de niveau de service (SLI) au-delà des métriques de
déploiement standards.
La maintenabilité sera renforcée par l'automatisation des mises à jour des dépendances et la mise en
place de tests automatisés plus robustes pour la logique backend et la fiabilité frontend.
8. Conclusion
Traiter un portfolio comme un système de production fournit une base pour la communication technique.
Cela convertit les affirmations abstraites en artefacts d'ingénierie vérifiables. Ces notes évolueront
parallèlement à la plateforme, servant de registre à long terme de la conception du système et de
l'apprentissage opérationnel.