Architecting for Infinite Scale: Provisioning AWS EKS with Terraform & Helm
In the DevOps and Platform Engineering world, there is a fundamental distinction between merely deploying an application and building a robust, scalable cloud deployment platform.
Recently, I architected the migration of my personal portfolio application—a standard two-tier architecture featuring a React frontend and a Node.js backend—from a localized bare-metal RKE2 cluster into the cloud utilizing Amazon Elastic Kubernetes Service (EKS).
The objective extended beyond simply running the workloads. The true objective was to engineer an Enterprise-grade Infrastructure-as-Code (IaC) pipeline. While I am deploying only two constituent microservices today, the infrastructure topology I designed is intrinsically capable of horizontally scaling to support 100+ microservices seamlessly, with zero modifications required to the underlying deployment logic.
Below is a comprehensive technical breakdown of how I designed and engineered this cloud-native environment, moving from raw Terraform modules to a declarative Helm rollout.
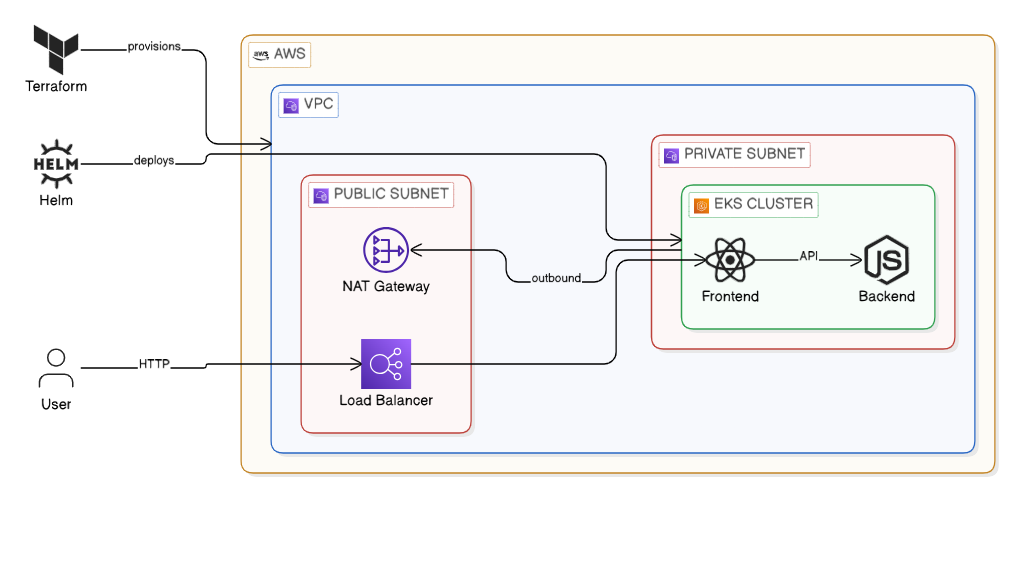
Figure 1: High-level architectural diagram of the EKS Infrastructure layered via Terraform and Helm.
Phase 1: The Infrastructure (Codified with Terraform)
A junior engineer builds infrastructure specifically for the workload immediately in front of them, usually by relying on "ClickOps" in the AWS Management Console. A senior engineer abstracts the infrastructure entirely through standardized code.
To guarantee that this environment remains 100% reproducible and state-managed, I modularized the AWS infrastructure utilizing Terraform. My project structure adopts best-practices for logical separation:
eks-infrastructure/
├── providers.tf # AWS provider and Terraform backend config
├── variables.tf # Dynamic variables for reusability
├── vpc.tf # The networking layer (Public/Private subnets)
└── eks.tf # The Kubernetes Control Plane and Node Groups1. Variables.tf (Making it Dynamic)
By defining explicit variables, different modular environments (e.g., staging vs. production) can be instantiated instantly.
variable "region" {
description = "AWS Region"
type = string
default = "eu-west-3"
}
variable "cluster_name" {
description = "EKS Cluster Name"
type = string
default = "portfolio-production-cluster"
}2. vpc.tf (The Network Foundation)
A resilient EKS deployment requires a robust network layer. I provisioned a custom Virtual Private Cloud (VPC) implementing public and private subnets, ensuring that the worker nodes sit securely behind a NAT Gateway—mitigating exposure to the public internet.
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "~> 5.0"
name = "${var.cluster_name}-vpc"
cidr = "10.0.0.0/16"
azs = ["${var.region}a", "${var.region}b"]
private_subnets = ["10.0.1.0/24", "10.0.2.0/24"]
public_subnets = ["10.0.101.0/24", "10.0.102.0/24"]
enable_nat_gateway = true
single_nat_gateway = true
enable_dns_hostnames = true
}3. eks.tf (The Compute Layer)
Compute cost is the primary bottleneck for cloud projects. I leveraged AWS Spot Instances for the underlying worker nodes to drastically slash compute costs without sacrificing application performance or reliability.
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.0"
cluster_name = var.cluster_name
cluster_version = "1.30"
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
cluster_endpoint_public_access = true
eks_managed_node_groups = {
standard_workers = {
min_size = 1
max_size = 3
desired_size = 2
instance_types = ["t3.medium"]
capacity_type = "SPOT" # FinOps: Crucial cost optimization strategy!
}
}
}Phase 2: Provisioning the Cluster
With infrastructure treated purely as software, orchestrating the entire AWS footprint requires merely three standard operations.
# Initialize Terraform backend and download AWS Provider modules
terraform init
# Review the deterministic execution plan
terraform plan
# Provision the VPC, NAT Gateways, and EKS Control Plane mapping
terraform apply --auto-approveOnce Terraform execution concludes successfully (typically around 15 minutes for the EKS Control Plane), I dynamically update my local configuration to context switch into the newly provisioned Cloud cluster:
aws eks update-kubeconfig --region eu-west-3 --name portfolio-production-clusterPhase 3: The Cloud Networking Gotcha & Helm Deployment
With the physical and virtual control plane online, workload deployment commenced utilizing a Helm Umbrella Chart.
However, migrating to an AWS-backed cloud environment introduced a specific networking challenge. Locally within RKE2, I resolved ingress traffic by setting my service type to NodePort. In AWS, traffic hitting random high-numbered NodePorts is automatically dropped by default EC2 Security Groups.
The elegant cloud-native solution involved a simple declarative modification to my values.yaml, specifically requesting an integrated cloud Load Balancer instead constraints:
# values.yaml
frontend:
service:
type: LoadBalancer
port: 80Following this single architectural modification, the unified frontend and backend deployment rolled out instantly:
helm install portfolio-app ./helm-portfolio-chart -n production --create-namespaceThe native AWS Cloud Controller seamlessly intercepts the LoadBalancer specification and automatically provisions a physical AWS Classic Load Balancer (ELB), mapping network traffic natively down into the appropriate Kubernetes pod ingress paths.
Results & Validation
The culmination of this IaC process presents a pristine, operational cloud architecture accessible to the public web.
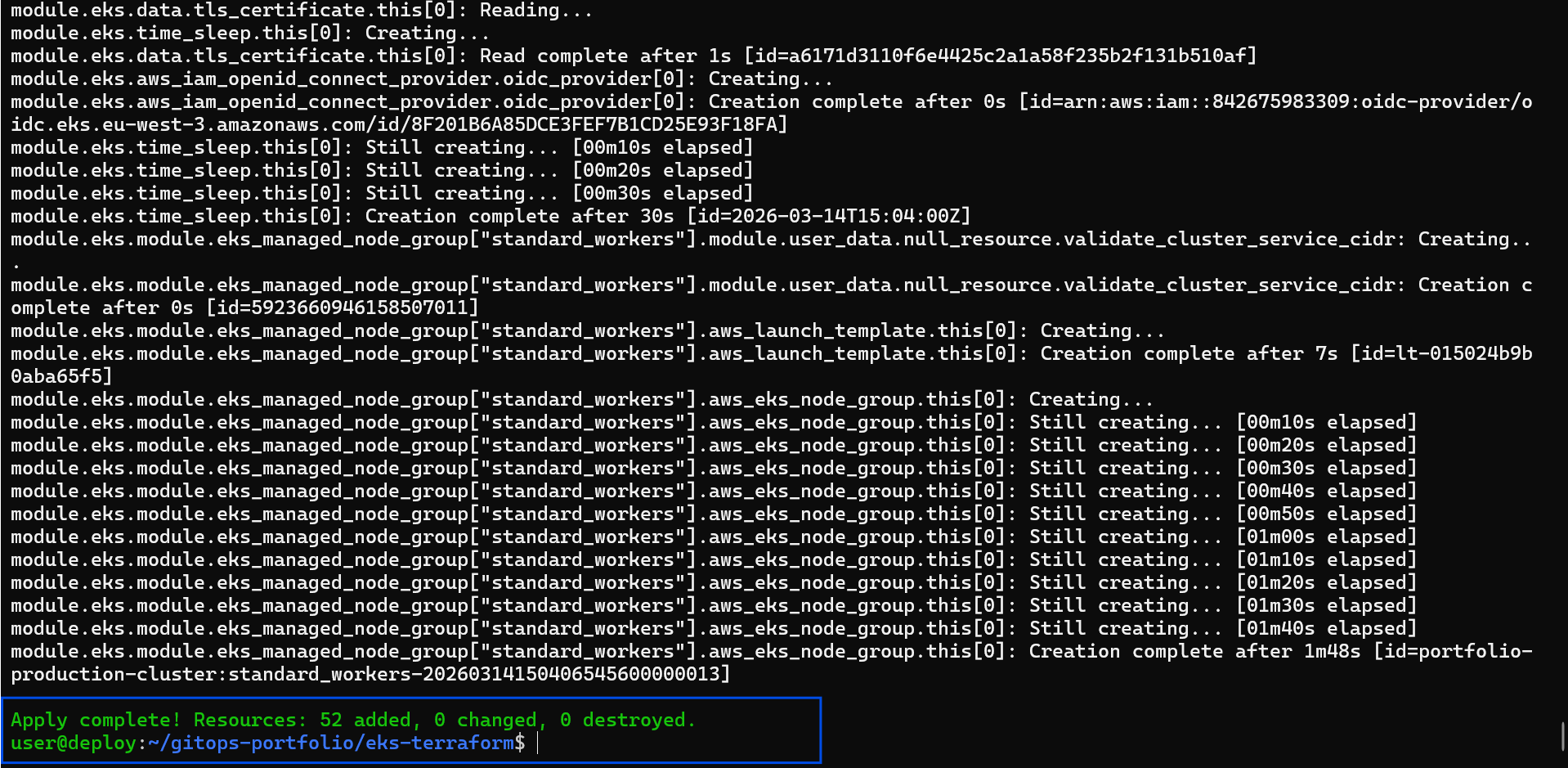
📸 Caption: Terraform successfully provisioning the AWS VPC, strict IAM boundaries, and the EKS Control Plane in a single automated workflow.
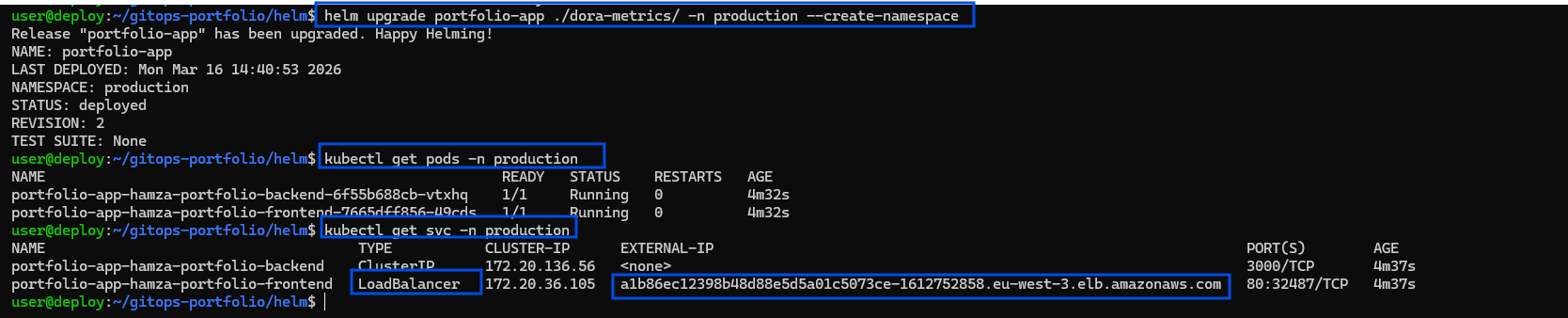
📸 Caption: Validating the deployment via `kubectl get pods,svc -n production`. Notice the generic LoadBalancer service autonomously assigning a public-facing AWS DNS endpoint for the portfolio site.
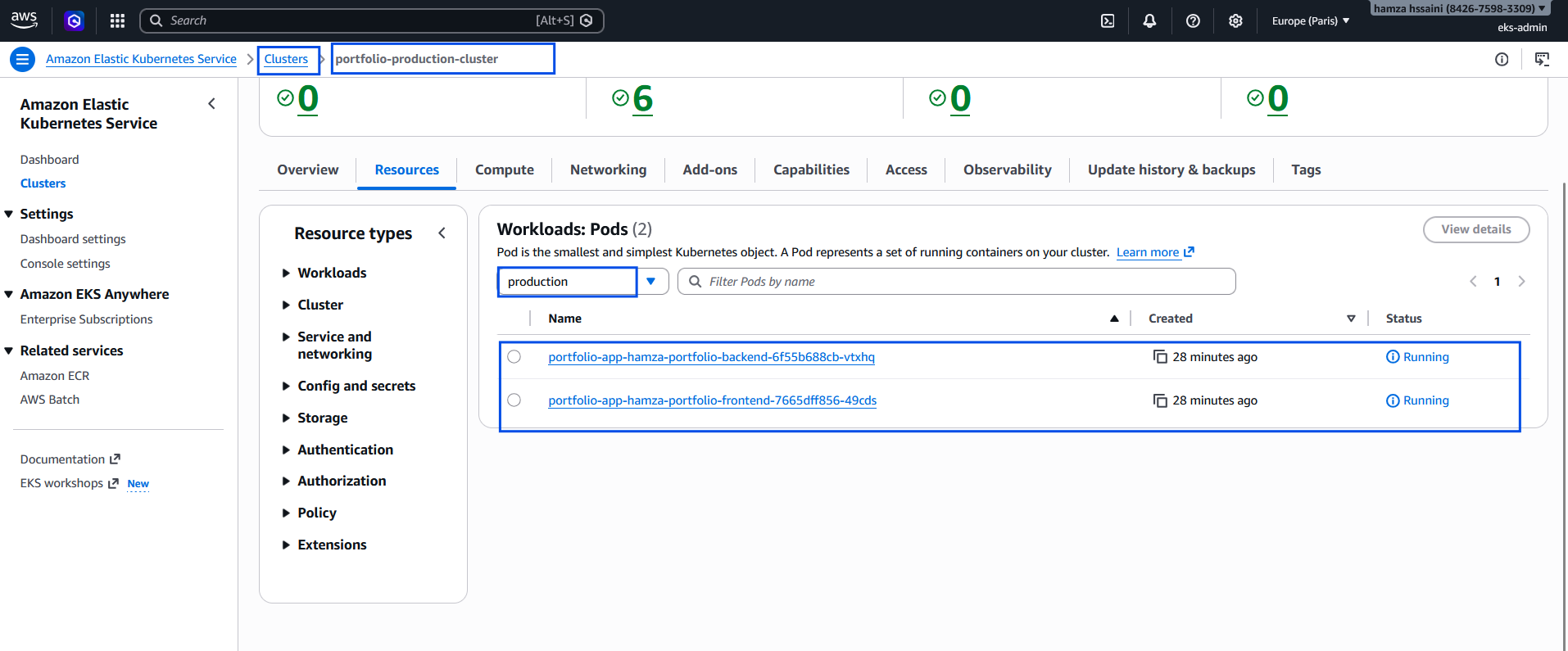
📸 Caption: Validating the deployment via via CONSOLE AWS, -n production`
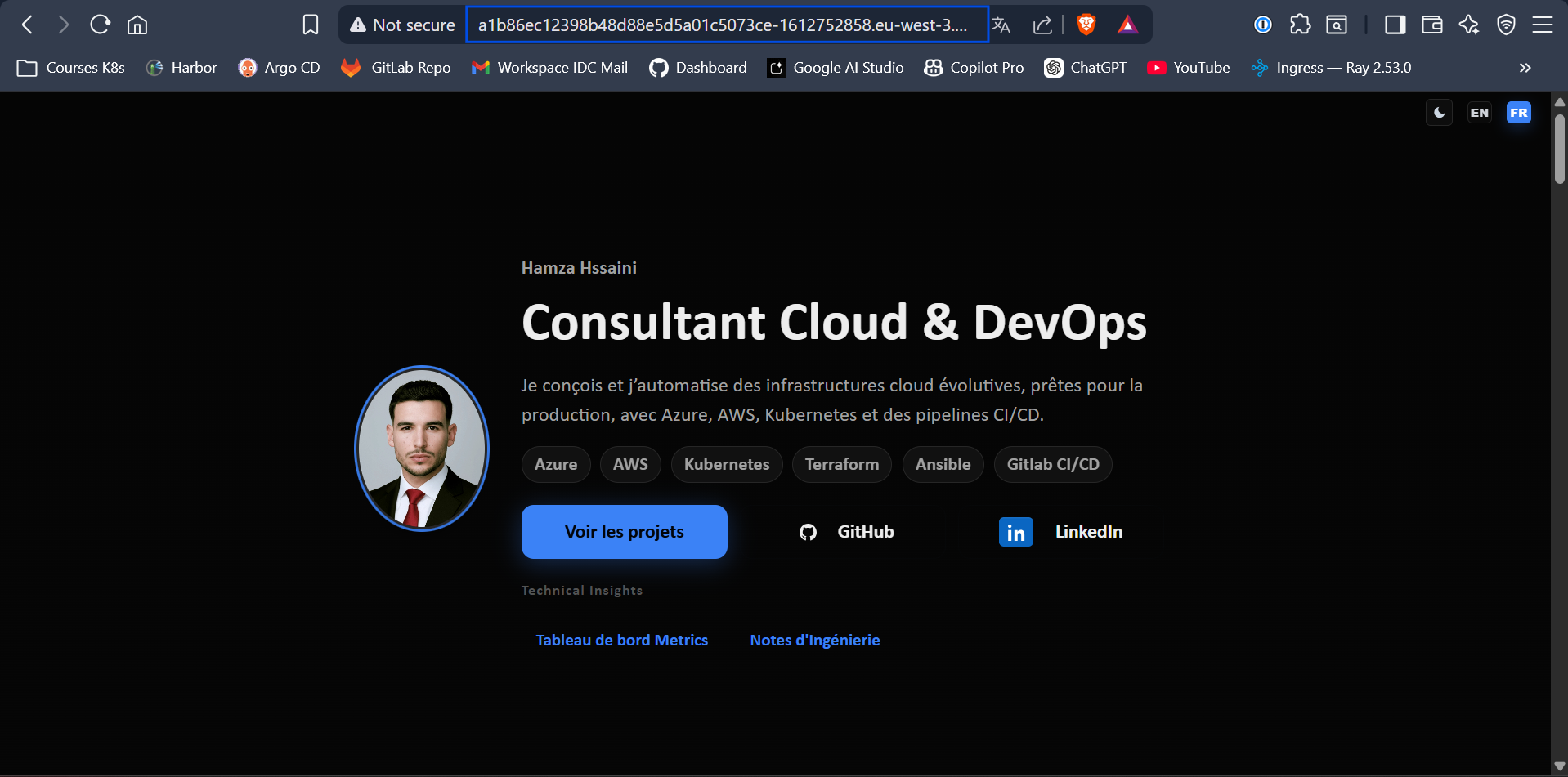
📸 Caption: Success! The portfolio frontend communicating reliably with the Node.js backend entirely over the public internet through the newly provisioned AWS ELB.
Troubleshooting AWS Guardrails & Security Traps
Enterprise cloud deployments rarely survive first contact with the cloud provider's API without hitting security or quota guardrails. During this migration, I encountered and resolved several advanced AWS and Kubernetes roadblocks. Documenting these challenges highlights the realities of transitioning from bare-metal orchestration to managed cloud environments.
1. Bypassing Cloud Sandbox Quotas (EC2 FinOps)
The Challenge: During the initial terraform apply, the EKS Managed Node Group creation failed with an AsgInstanceLaunchFailures error, stating the instance type was not eligible for the Free Tier. Because I was operating within a strict AWS promotional credit sandbox, AWS instituted hard guardrails against provisioning standard t3.medium compute nodes.
The Fix: Instead of blindly guessing allowed instance types, I queried the AWS API directly using the CLI to discover exactly what the sandbox would allow:
aws ec2 describe-instance-types --filters "Name=free-tier-eligible,Values=true" --query "InstanceTypes[*].InstanceType" --region eu-west-3
Figure 4: Querying the AWS EC2 API to dynamically discover Free-Tier eligible architectures in the eu-west-3 region to bypass Sandbox quotas.
This revealed that t3.small (2GB RAM) was permitted. I dynamically updated my Terraform variables to inject t3.small into the ASG (Auto Scaling Group) launch template, successfully bypassing the sandbox quota while securing enough memory to avoid OOMKilled errors for my system pods.
2. AuthN: The "Provide Credentials" Trap
The Challenge: After successfully provisioning the cluster and updating my local kubeconfig to use my eks-admin profile, my kubectl client aggressively rejected my connection:
user@deploy:~/gitops-portfolio/eks-terraform$ kubectl get nodes
E0316 13:47:03.803824 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: the server has asked for the client to provide credentials"
error: You must be logged in to the server (the server has asked for the client to provide credentials)The Root Cause & Fix: This is a classic Authentication (AuthN) failure. Even though my AWS CLI was generating valid STS tokens locally, the modern EKS Control Plane uses a strict Access Entries system. Because my eks-admin IAM user was not officially registered inside the EKS cluster's identity map, Kubernetes simply refused to acknowledge the token.

Figure 5: Diagnosing the 401 Unauthorized API error. The EKS Control Plane was rejecting the AWS STS token because the IAM Principal was not mapped.
I resolved this by navigating to the AWS EKS Console and explicitly creating a new Access Entry for my arn:aws:iam::842675983309:user/eks-admin principal, officially bridging my AWS identity with the Kubernetes API.
3. AuthZ: The 403 Forbidden RBAC Error
The Challenge: Immediately after fixing the credentials issue, I ran kubectl get nodes again and hit the next layer of security:
Error from server (Forbidden): nodes is forbidden: User "arn:aws:iam::842675983309:user/eks-admin" cannot list resource "nodes" in API group "" at the cluster scopeThe Senior Fix: This is a textbook Authorization (AuthZ) error. EKS now recognized who I was (Authentication), but I had zero permissions inside the cluster (Authorization). Creating an Access Entry is not enough; it must be bound to a strict Role-Based Access Control (RBAC) policy.

Figure 6: The AuthZ roadblock. The cluster successfully authenticated the user, but strict RBAC rules prevented resource discovery.
To fix this, I attached the AmazonEKSClusterAdminPolicy directly to my Access Entry within the AWS GUI at the cluster scope. Instantly, my eks-admin user was granted full cluster orchestration rights, and the worker nodes appeared in my terminal.
4. Zero-Trust Identity Mismatch (CLI vs. GUI)
The Challenge: While I could now successfully orchestrate my pods via the CLI, logging into the AWS EKS Web Console displayed: "This cluster does not have any Pods, or you don't have permission to view them."
The Fix: This perfectly illustrates the disconnect between terminal sessions and browser sessions. My Linux terminal was authenticated via the eks-admin IAM Access Keys, but my web browser was still authenticated as the AWS Root user.
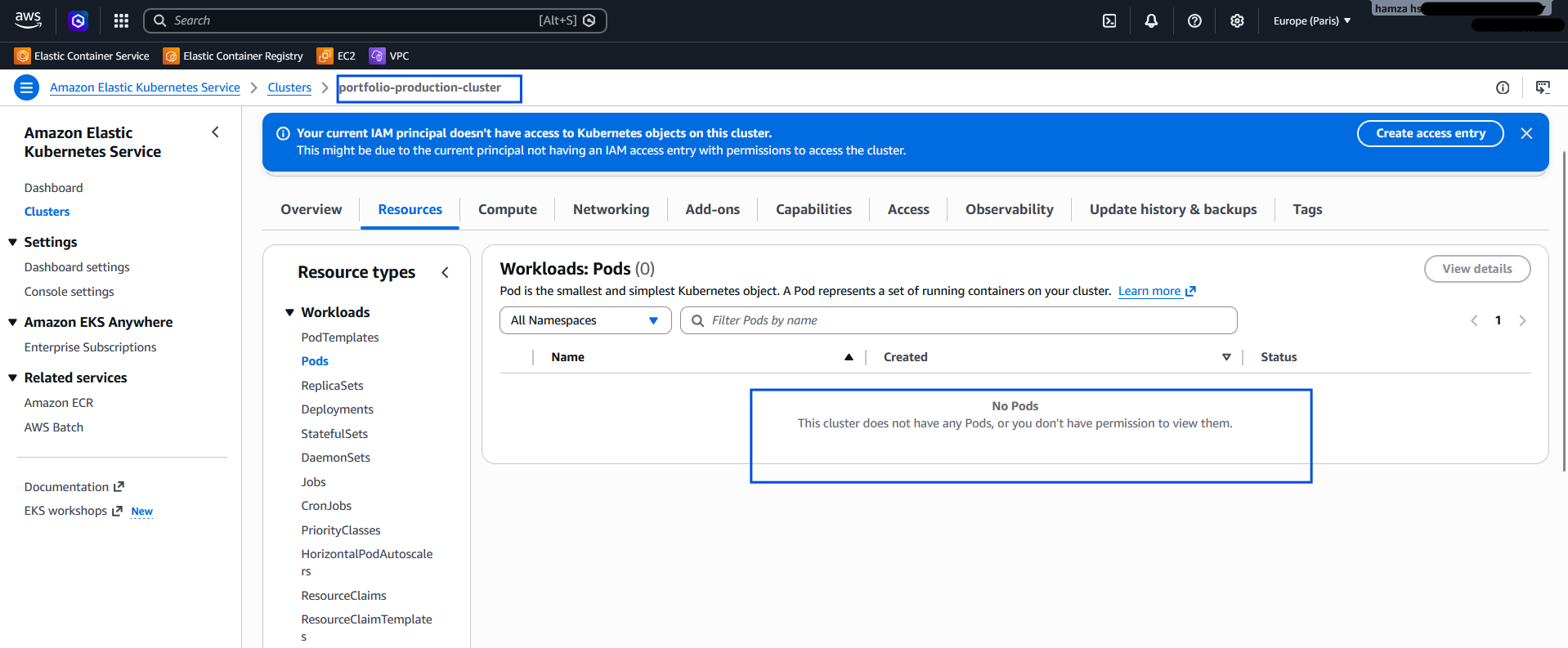
Figure 7: Resolving the CLI vs. GUI mismatch. The AWS Console correctly hid the workloads from the unauthorized Root session, enforcing true Zero-Trust architecture.
Because I strictly isolated my Kubernetes RBAC bindings to the eks-admin identity, the AWS Console correctly hid the workloads from the unauthorized Root session. By generating a console password for eks-admin and switching browser sessions, I aligned my GUI identity with my CLI identity, successfully visualizing my workloads.
5. Asynchronous Cloud Networking (The DNS Delay)
The Challenge: Upon deploying my Helm Umbrella chart, AWS successfully provisioned a Classic Load Balancer (ELB). However, accessing the provided .elb.amazonaws.com endpoint immediately resulted in a DNS_PROBE_POSSIBLE browser error.
The Fix: In localized environments, NodePorts bind instantly. In the cloud, infrastructure is asynchronous. This error simply indicated that AWS Route53 required 3 to 5 minutes to propagate the newly generated A-Records across global DNS resolvers. Understanding this cloud timing mechanism prevented unnecessary debugging; after a brief propagation window, the application resolved perfectly over the public internet.
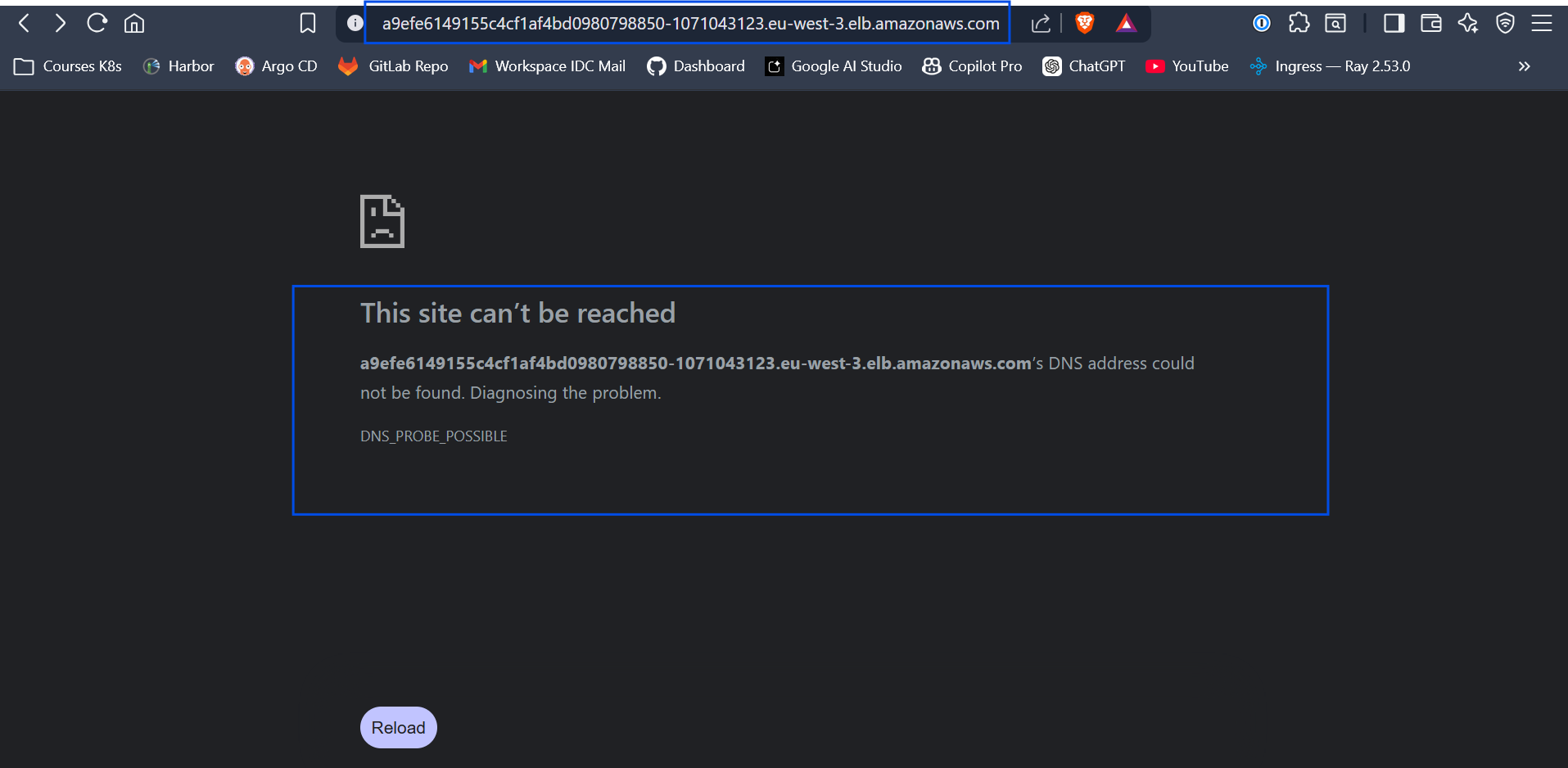
Figure 8: The browser showing the DNS_PROBE_POSSIBLE browser error.
FinOps & Cost Management: Embracing Ephemeral Infrastructure
Managed cloud environments possess immense capabilities, but they inherently carry substantial billing implications. The managed EKS Control Plane independently incurs roughly $73/month. Because I am currently operating on a strict $53 AWS promotional credit margin, leaving this cluster perpetually running would completely drain my budget within weeks.
This highlights the ultimate leverage of strict Infrastructure as Code. Because my entire environment is thoroughly codified and stateless, my cluster itself can act as ephemeral infrastructure. At the end of my technical sessions, I reduce my daily AWS burn rate back down to strictly $0.00 by executing:
terraform destroy --auto-approve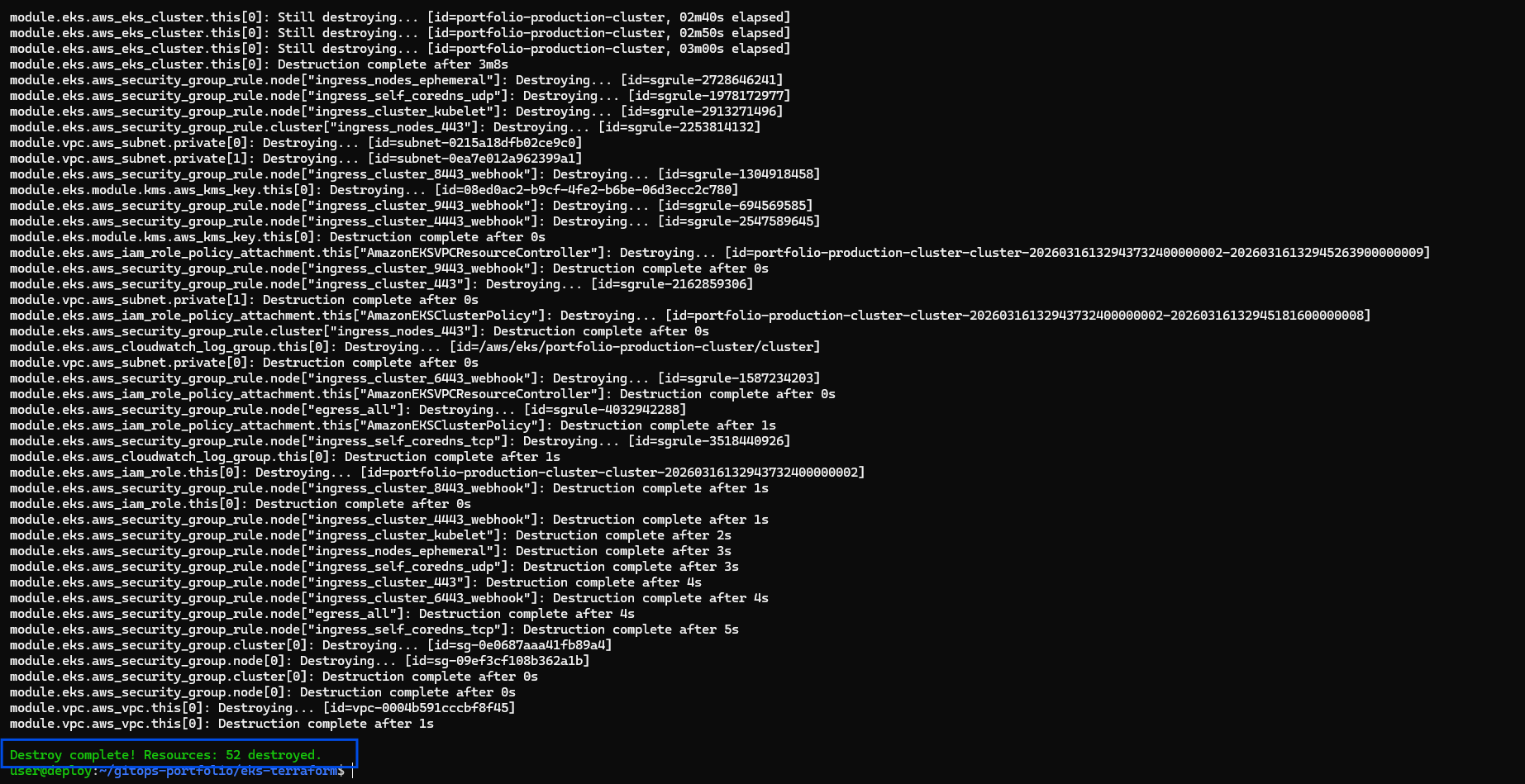
Executing infrastructure tear-down to maintain zero AWS spend during inactive hours.
The following morning? A single terraform apply and one sequential helm install later, and my fully resilient, production-grade EKS cloud layout is entirely rebuilt from absolute scratch and resolving traffic.
Conclusion
Migrating my workloads from on-premise localized orchestration into AWS EKS proves definitively that Kubernetes remains the ultimate computing equalizer. By layering Terraform for rock-solid deterministic infrastructure and Helm for agile application delivery, I successfully built a platform-agnostic enterprise pipeline.
Whether I am deploying a rudimentary two-tier portfolio architecture or maintaining a massive 100-service AI processing platform, the fundamental pipeline remains utterly identical, aggressively automated, and infinitely scalable.